AI为何被困在内存墙中:一场从算力堆砌到数据流效率的战争
AI竞争正从算力堆砌转向数据流效率之争。传统GPU高达90%的能量消耗在数据搬运而非计算上,冯诺依曼架构的"内存墙"成为AI发展的真正瓶颈。业界分化出四条突围路径:存内计算消灭搬运,硅光互联用光子击穿带宽瓶颈,确定性/专用化架构牺牲灵活性换取极致效率,CPU回归实现数据流精细化治理。
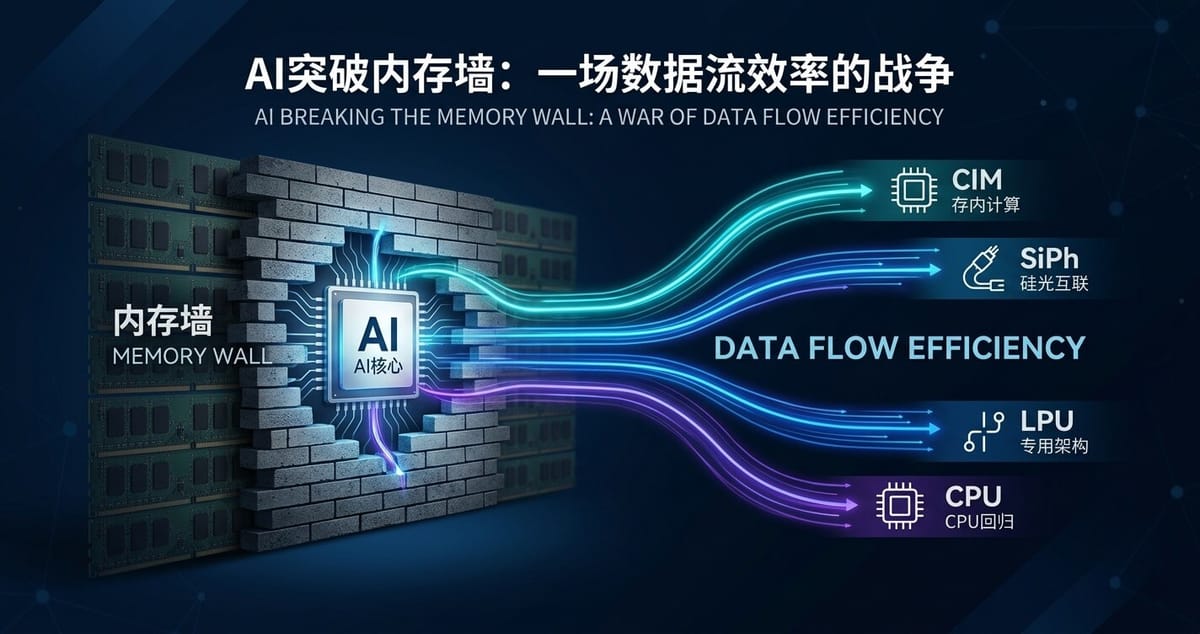
内存危机:两个标志性事件揭开AI真正的瓶颈
最近有两件事,放在一起看特别有意思。
第一件:英伟达宣布以约200亿美元收购Groq。200亿美元,这个数字本身就够震撼了。但更值得琢磨的是——英伟达买的到底是什么?Groq不是一家传统意义上的GPU公司,它做的是一种叫LPU(Language Processing Unit)的东西。LPU的核心思路很"反常识":不外挂HBM,用片上SRAM做主存,把数据搬运这件事尽可能消灭掉。英伟达花这么大价钱,买的不是更多的算力,而是一种全新的架构思路。
这说明什么?说明连英伟达自己都意识到了,光堆算力这条路,快走到头了。
第二件:全球内存价格暴涨。DDR4 16GB内存的价格,从3.2美元一路飙到62美元,涨幅高达1800%。不只是DDR4,DDR5在涨,连早该退役的DDR3都在涨。整个科技行业正面临一场前所未有的内存短缺危机。
这两件事看起来一个是收购新闻,一个是供应链危机,似乎没什么关系。但如果你把它们放在一起,会发现它们指向同一个矛盾:AI竞争的核心战场,正在从算力堆砌转向数据流效率。
换句话说,"内存墙"才是制约AI发展的真正瓶颈。
要理解这堵墙,得先看看内存的层级结构。芯片世界里的存储大致分三层:
- SRAM:速度极快,就在计算单元旁边,但贵得离谱,而且占芯片面积大。
- DRAM:容量大,价格相对便宜,但速度比SRAM慢一个数量级,功耗也高。
- HBM(高带宽内存):把多层DRAM堆叠起来,用硅通孔(TSV)连接,带宽大幅提升。听起来像是完美方案,但成本高昂、产能紧张,厂商们望梅止渴。
每一层都有自己的硬伤。而AI模型越来越大,对内存带宽和容量的需求几乎是无底洞。这就是困局所在。
内存墙的本质:冯诺依曼架构下,计算在等待数据
很多人以为AI芯片的瓶颈是算力不够。其实不是。
一个让人吃惊的数据:无论是英伟达的H100还是最新的B200,传统GPU在执行AI计算时,高达90%的能量和时间消耗在数据搬运上,真正用于计算的部分只有大约10%。
90%。这个数字值得反复品味。
为什么会这样?根源在于一个70多年前就确立的架构——冯诺依曼架构。
冯诺依曼架构的核心特征是存储与计算物理分离。数据存在内存里,计算发生在处理器里。要算东西,就得先把数据从内存搬到计算单元,算完再搬回去。这个过程听起来简单,但在实际芯片中,这条"搬运之路"消耗的能量和时间远超计算本身。
你可以把它想象成一个工厂:工人的手速极快,但原材料的仓库离车间很远。工人大部分时间不是在干活,而是在等材料送过来。
这就是所谓的"冯诺依曼瓶颈",也有人叫它"内存墙"。
关键在于,这不是一个靠堆晶体管或者提升制程就能解决的问题。你可以把制程从7nm缩到3nm,可以把带宽从几百GB/s拉到几TB/s,但只要存储和计算还是物理分离的,这笔"搬运税"就永远存在。距离可以缩短,但不会消失。
这是架构层面的根本性矛盾。
正因为如此,业界开始分化出截然不同的技术路径来应对内存墙。不是一条路,而是四条。它们的思路各不相同,有的试图从根源消灭搬运,有的试图绕开它,有的试图击穿它,还有的试图精细化治理它。
存内计算:让内存自己学会"算"
第一条路径,也是最具根本性的一条:存内计算(Computing-in-Memory)。
思路很直接——既然数据搬运是问题的根源,那干脆别搬了。让数据待在存储单元里,就地完成计算。
这不是天方夜谭。存储介质本身就有物理特性可以利用。比如SRAM的位线上,多个存储单元的电流可以叠加,这个叠加本身就是一种加法运算。再比如ReRAM(阻变存储器)和MRAM(磁阻存储器),它们的电阻状态可以用来表示权重,电流通过时自然完成乘法和累加。
存储即计算。这个概念听起来很美。
目前存内计算有两条主要的技术路线:
PNM(Processing-Near-Memory,近存计算),三星是这个方向的主要推动者。做法是在存储芯片内部集成独立的计算单元。数据不用流出内存颗粒,在"仓库门口"就完成初步处理。这种方式特别适合参数量巨大的大模型加速,因为模型权重本来就存在内存里,就近算完就行。
CIM(Computing-in-Memory,真正的存内计算),比PNM更激进。它不是在内存旁边放一个计算单元,而是直接利用存储单元本身的物理特性来做运算。计算发生在内存的"细胞"内部。这条路线更具颠覆性,但技术挑战也更大。
挑战确实不小。首先是软件生态几乎空白,现有的EDA工具和编程框架都不是为存内计算设计的。其次是模拟电路固有的噪声问题、工艺偏差、器件一致性——这些在传统数字电路中不太操心的事,在存内计算里都是大麻烦。
目前存内计算正处于从实验室走向量产的关键阶段。说实话,离大规模商业化可能还需要数年时间。
但它的战略意义不容忽视。在所有应对内存墙的技术路径中,存内计算是唯一试图从源头消灭数据搬运的方案。其他路径或多或少都是在"搬运"这个前提下做优化,只有存内计算说:我不搬了。
硅光互联、确定性架构与CPU回归:三条差异化路径
除了存内计算,还有三条路径在同时推进。它们的策略各不相同,但目标一致:打破内存墙的束缚。
路径二:硅光互联——用光子击穿互联墙
数据搬运的问题,不只发生在芯片内部。在大规模AI集群中,芯片与芯片之间、机架与机架之间的数据传输同样是巨大的瓶颈。
传统方案用的是电信号。电信号在PCB板上跑几十厘米,功耗和延迟就已经很可观了。当你要搭建一个万卡GPU集群时,这些走线上的损耗会变成一个天文数字。
硅光互联的思路是:用光代替电。
具体做法是把光器件(调制器、探测器、波导等)直接集成在硅芯片上,与计算芯片封装在同一基底。光信号的优势非常明显:
- 极致能效:信号损耗从传统电互联的22dB降至4dB以内。
- 超高带宽:利用波分复用技术,单根光纤可以承载多个波长的信号,8对光纤就能实现双向4Tbps的带宽。
- 支撑大规模集群:这种带宽水平足以支撑万卡级GPU集群的机架间互联需求。
博通、台积电等巨头已经全面入场。硅光技术正在模糊网络与计算的界限。更深远的影响在于,它使内存池化、资源解耦等新型数据中心架构成为可能——内存不再绑定在单个芯片上,而是可以通过光互联共享和调度。
路径三:确定性与极端专用化——牺牲灵活性换极致效率
这条路线的逻辑很"暴力":既然通用架构在内存墙面前左右为难,那就别通用了。
Groq的LPU就是这个思路的代表。它摒弃了外挂HBM,采用数百MB的片上SRAM作为主存。片上SRAM的带宽高达80TB/s,是传统GPU的10倍以上。同时,LPU摒弃了乱序执行和分支预测这些传统处理器的"灵活性"设计,把调度权完全交给编译器。一切都是预先确定的,追求的是零抖动、零延迟的确定性执行。
这就是英伟达愿意花200亿美元买下来的东西。
还有更极端的。Etched的HC1芯片,直接把Llama 3.0 18B模型的权重固化在芯片的金属掩膜层中。没错,模型参数直接"印"在芯片里,彻底绕开了HBM,数据搬运降至零。
代价是什么?一颗芯片只能跑一个模型。不能更新,不能切换。
换来的是什么?10倍能效提升,20倍成本下降,推理速度达到17000 tokens/s——这是英伟达B200的48倍。
这条路线的本质是:不再试图调和通用性与性能之间的矛盾,而是用"确定性"和"专用化"直接绕开内存墙。你不需要搬运数据,因为数据已经在那里了,或者说,数据就是芯片本身。
路径四:CPU角色回归——数据流的智能管家
最后一条路径,可能是最容易被忽视的:CPU的回归。
AI正在从对话时代走向Agent时代。Agent不只是生成文本,它要调用工具、访问数据库、执行代码、与外部系统交互。这些任务中有大量的逻辑判断、分支控制、I/O操作——这些恰恰是CPU擅长的事情。黄仁勋自己都明确说过,Agent时代CPU的角色至关重要。
从理论层面看,这里有一个经典的约束:阿姆达尔定律。它告诉我们,当你把并行计算加速到极限之后,整个系统的瓶颈最终会落在那些无法并行的串行部分上。GPU再快,串行部分的天花板还是由CPU决定。
CPU应对内存墙的方式和前面几条路径都不同。它不试图消灭内存层级,也不追求极端专用化,而是通过精细化的数据流治理和智能共享机制,在不大幅提升内存配置的前提下,兼顾能效比与可编程性。
某种意义上,CPU开辟了通用GPU与极端专用化之间的"第三条道路"。它不是最快的,但可能是最务实的。
内存焦虑不是终点:AI硬件竞争的底层逻辑已经逆转
回过头来看这四条技术路径:
- 存内计算,从根源消灭搬运;
- 硅光互联,用光子击穿互联瓶颈;
- 确定性/专用化架构,牺牲灵活性绕开内存墙;
- CPU回归,精细化治理数据流。
方向各异,但指向同一条主线:AI硬件竞争已经从"谁的算力更强"转向"谁的数据流效率更高"。
内存墙的本质,不是内存不够大。而是数据搬运的代价太高。
未来的赢家,不会是堆最多HBM的人,而是能让海量数据以最低能耗、最高确定性,在存储与计算之间高效流动的人。
也不会有单一的银弹。未来的AI硬件生态,大概率是存内计算、硅光互联、专用芯片、智能CPU协同演进的格局。每种方案都有自己的适用场景和局限性,谁也替代不了谁。
借用《侏罗纪公园》里那句经典台词:"生命总能找到自己的出路。"
内存焦虑不会是终点。技术演化终将突破这堵墙。只是突破的方式,可能不是我们今天想象的任何一种单一路径,而是多条路径交织、协同、共同演进的结果。



