NVLink深度解析:从技术原理到实战性能,彻底搞懂GPU互联
从技术原理、实测数据和应用场景三个维度,深入解析了NVLink与PCIe两种GPU互联方式的核心差异。实测表明,低并发下两者差别不大,但高并发场景中PCIe在吞吐量、首字延迟和尾部延迟上均出现瓶颈。文章给出了场景决策建议:个人轻量使用选PCIe,生产级AI服务必须考虑NVLink。
引言:GPU够强就够了吗?被忽视的互联瓶颈
很多人在购买GPU服务器或者搭建本地大模型推理环境时,都有一个根深蒂固的想法——"卡只要够贵够强,模型自然就能跑起来。"
但事实真的是这样的吗?
实际上,当你从"能跑"走向"跑得好",从"自己用"走向"给别人用"的时候,GPU本身的算力可能根本不是瓶颈。真正卡脖子的地方,往往藏在一个大多数人不太关注的环节——GPU之间的数据传输。
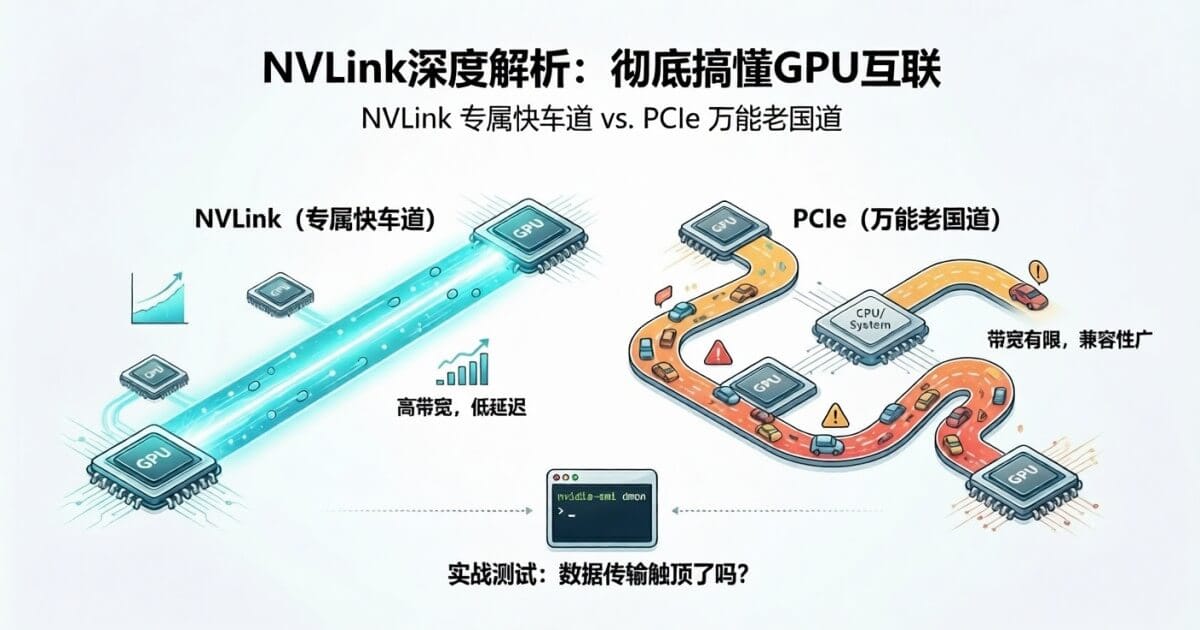
NVLink和PCIe,是目前两种主流的GPU互联方式。它们在带宽、延迟、扩展性和成本上存在显著差异。选对了,系统性能一路畅通;选错了,花再多钱买的卡也只能在那干瞪眼。
这篇文章不讲玄学,不搞信仰充值。我们从技术原理、实测数据、应用场景三个维度,系统梳理NVLink到底值不值得买,以及什么时候该买。
NVLink是什么?与PCIe的本质区别
NVLink:NVIDIA的"专属快车道"
NVLink是NVIDIA推出的一种专有高速GPU互联技术。它的诞生目的非常明确——突破传统PCIe总线在GPU间数据传输上的带宽瓶颈。
简单来说,NVLink通过专用的物理接口和通信协议,让GPU与GPU之间可以"直接对话",不需要绕路,不需要中转,速度快、延迟低。
PCIe:万能的"老国道"
PCIe(Peripheral Component Interconnect Express)是计算机世界里的通用总线标准。它的兼容性堪称"全能冠军"——显卡、网卡、存储卡、各种加速卡,几乎所有设备都能插上去用。
但PCIe的设计初衷并不是专门给GPU之间搬运大规模数据用的。它更像一条老国道:什么车都能跑,但路就那么宽,遇到高峰期该堵还是堵。
核心差异一览
| 对比维度 | NVLink | PCIe |
|---|---|---|
| 带宽 | 远超PCIe,可达数百GB/s(取决于代际) | 受限于通道规格,如PCIe 5.0 x16约64GB/s |
| 拓扑结构 | 支持多卡直连的网状拓扑(如8卡全互联) | 多卡通常需经CPU或PCIe交换芯片中转 |
| 兼容性 | 需要特定硬件支持(专用接口、桥接器、底板) | 几乎所有设备都支持,即插即用 |
| 成本 | 桥接器/底板额外投入,整体成本较高 | 无额外互联成本,部署成本低 |
| 适用规模 | 大规模并行、高并发生产环境 | 轻量级应用、单卡或少量多卡场景 |
物理形态上的区别
NVLink的物理载体主要有两种形态:
- NVLink桥接器:最常见的是双卡桥接器,像一个小桥一样架在两张GPU之间,实现两卡直连。比如在H100液冷4卡服务器上,加一组NVLink桥接器就能让相邻两张卡之间的带宽大幅提升。
- NVLink底板(Baseboard):用于四卡或八卡模组,所有GPU通过底板实现全互联。典型代表就是NVLink 8卡模组,八张卡之间可以像一个整体一样协同工作。
不同的形态对应不同的部署规模。双卡桥接适合小规模升级,底板模组则面向追求极致性能的大规模部署。
实测数据说话:NVLink vs PCIe的性能真相
光讲理论没意思,我们直接看数据。
低并发:看起来都差不多
在低并发场景下——比如单用户对话、简单的推理任务——加不加NVLink,体感差别确实不大。PCIe和NVLink"看起来都挺快"。
这一点在实测中也得到了验证。使用LLAMA.cpp等框架做单用户推理测试,PCIe插槽直连和雷电外接显卡坞的数据差别也不大。正因如此,很多人得出了"NVLink对推理没用"的结论。
但这个结论是错的,或者说,是以偏概全的。
单用户测试压根就没有触发并发机制,GPU之间的数据交换量很小,PCIe的带宽绰绰有余。在这种场景下评估NVLink,就像在空旷的马路上比较自行车道和高速公路——当然看不出区别。
高并发:差距急剧拉大
真正的分水岭出现在并发量上来之后。
以H100四卡服务器为例,有NVLink桥接器和没有NVLink桥接器的对比测试数据非常说明问题:
吞吐量表现:
| 并发数 | PCIe(无NVLink) | NVLink |
|---|---|---|
| 1-10 | 表现正常,差别不大 | 表现正常,差别不大 |
| 30-40 | 吞吐基本卡住,不再增长 | 吞吐持续上升 |
| 100+ | 反而开始变慢,性能下降 | 状态稳定,持续增长 |
注意看100+并发那行。PCIe不是"不够快",而是"反而变慢"了。这是什么意思?卡和卡之间堵车了,数据传输跟不上了,GPU空转等数据,整体效率反而下降。
首字延迟(Time to First Token):
这个指标衡量的是用户发出请求后,多久能看到第一个字的回复。在高并发下,PCIe环境中等第一个字经常要十几秒。十几秒是什么概念?实际业务里,用户早就以为系统挂了,开始疯狂刷新或者直接走人。
而NVLink还能把首字响应时间压在用户可接受的范围内。
尾部延迟(P99/最慢请求):
这才是真正拉开差距的"杀手级指标"。
P99延迟指的是99%的请求都能在这个时间内完成——也就是说,只看那最慢的1%。在高负载下,PCIe环境中会出现几分钟才返回结果的极端情况。几分钟啊!这意味着什么?
接口超时 → 请求堆积 → 整个服务被拖死
一个几分钟不返回的请求,可能会像多米诺骨牌一样把整条链路全部打崩。而NVLink能有效避免这种灾难性的长尾延迟,把最慢的那批请求也控制在合理范围内。
数据传输监测:眼见为实
说了这么多,有人可能会问:你怎么知道是GPU间数据传输的问题,而不是别的什么瓶颈?
答案是可以直接监测。NVIDIA提供了一个非常实用的命令:
nvidia-smi dmon -s pucvmet这条指令可以实时监测每张GPU的各项状态,其中最关键的是RX(接收)和TX(发送)数据速率。
在实际的大模型推理过程中,实测观察到TX峰值达到了约6816 MB/s(约6.8 GB/s)。这个数字说明什么?说明在推理过程中,GPU之间需要搬运的数据量非常大,已经逼近甚至触及了PCIe带宽的上限。
进一步的验证来自跨网络的RPC分布式推理实验。把两张卡分布在不同的机器上,通过网络连接进行分布式推理,结果非常直观:网络带宽(等效于GPU互联带宽)直接制约推理性能。网速快,推理快;网速慢,推理慢。没有任何含糊地带。
如何正确理解NVLink的价值?问题转换的思维方法
你可能一开始就问错了问题
社区里经常有人问:"NVLink对大模型推理有没有用?"
坦率说,这个问题太笼统了。就好比问"运动对健康有没有好处"——答案当然是"看情况",但这个"看情况"对你做决策毫无帮助。
换一个问法
正确的问题应该是:
在我的具体推理场景中,GPU之间的数据传输峰值达到了什么水平?是否已经逼近PCIe速率的上限?PCIe速率是否已经成为我的性能瓶颈?
把问题从抽象的"有没有用"转化为具体的"数据传输是否触顶",一切就清晰了。这个思路的核心就是——与其争论NVLink对推理起到什么作用,不如直接观察推理过程中两张显卡之间的数据传输达到了怎样的程度。
几个常见的认知偏差
偏差一:用单用户测试下结论
LLAMA.cpp直接对话,跑个单用户推理,PCIe和NVLink表现差不多。于是得出"NVLink对推理没用"的结论。
问题在于:单用户场景几乎不触发GPU间的大规模数据交换。这就好比在一条空旷的乡间小路上测试,说"四车道和八车道没区别"。等到早高峰的时候再看看?
偏差二:雷电外接方案"够用了"
有人用雷电外接显卡坞搭了个"极简方案",单用户跑起来数据还不错,就觉得这套方案万事大吉。但雷电接口的带宽更窄,一旦涉及并发或更大的模型,互联带宽立刻变成瓶颈。
偏差三:忽略推理框架的差异
不同的推理框架对并发的支持能力差别很大。LLAMA.cpp、vLLM、OneCat VLM等框架各有特点。用一个不太支持并发的框架做测试,得出"并发没影响"的结论,这是框架的问题,不是NVLink的问题。
实操方法:自己动手测
与其在网上争论,不如自己动手验证。方法很简单:
- 启动你的推理任务(用你实际的业务场景,而非简单的单用户对话)
- 让推理跑一段时间,收集数据
- 分析
gpu_monitor.txt中的TX/RX数据,看峰值是否触及PCIe带宽上限
在另一个终端运行:
nvidia-smi dmon -s pucvmet > gpu_monitor.txt如果峰值已经逼近上限——恭喜,你找到了瓶颈,NVLink对你来说是必要的投入。如果峰值离上限还远——那PCIe够用,省下的钱可以花在别处。
用数据说话,不用信仰做选择。
场景决策指南:谁需要NVLink,谁不需要?
到这里,理论和数据都摆清楚了。最终还是要落到一个实际问题上:我到底该不该买NVLink?
不需要NVLink的场景
以下几种情况,PCIe方案完全够用,没必要为NVLink额外掏钱:
- 个人用户本地跑大模型:自己玩玩,跑跑对话,单用户推理,PCIe绰绰有余。
- 内部测试和模型调试:如果你只是内部测试,怎么配都行。模型能加载、能跑通、能看结果就够了。
- 小规模实验和学习研究:做做实验、写写论文、调调参数,不需要考虑并发和稳定性。
- 预算有限的轻量级应用:PCIe方案"低调实用",兼容性好,成本低,简单替换或新增一张卡就能提升性能。
PCIe最大的优势就是灵活和便宜。不需要额外的桥接器或底板,几乎任何服务器都能直接上,维护也简单。
必须考虑NVLink的场景
但如果你的场景涉及以下任何一项,NVLink就不再是"可选配件",而是工程底线:
- 对外提供推理服务:API接口对外开放,需要承载几十甚至上百并发请求的生产环境。
- 企业级AI服务:需要稳定、低延迟、高吞吐,不能出现接口超时或服务崩溃。
- 大规模训练任务:多卡并行训练大模型,GPU间需要频繁同步梯度和参数。
- 追求极致性能的专业用户:做性能优化、做基准测试、做极端场景验证。
在这些场景里,NVLink不是让你"跑得更快一点"的锦上添花,而是防止你"在关键时刻崩掉"的基本保障。
NVLink 8卡模组 vs PCIe多卡
如果决定上NVLink,还面临一个选择:是用NVLink桥接器做双卡/四卡互联,还是直接上8卡全互联模组?
| 方案 | 优势 | 劣势 | 适合谁 |
|---|---|---|---|
| NVLink 8卡模组 | 全互联、性能天花板高、可灵活扩展 | 成本高、需考虑系统兼容性 | 不断寻求性能突破的团队 |
| NVLink桥接器(双卡/四卡) | 成本适中、对现有系统改动小 | 互联范围有限 | 中等规模生产环境 |
| PCIe多卡(无NVLink) | 兼容性好、成本低、部署简单 | 高并发瓶颈明显 | 预算有限或场景简单的用户 |
NVLink 8卡模组有人形容得很好——"如同变形金刚的组合变身",多张卡拼成一个整体,性能指数级提升。但前提是你的业务确实需要这样的规模。
晨涧云GPU算力平台支持NVLink 8卡模组的A800 80G和40G显卡出租,可以来体验下NVLink多卡互联性能。
成本与收益的权衡
NVLink底板或桥接器的额外成本到底值不值?这取决于一个关键判断:
如果高并发下的尾部延迟会导致服务崩溃,那NVLink的投入就不是"性能提升",而是"必要保障"。
想想看:一次P99延迟几分钟的请求,触发接口超时,导致请求堆积,最终把整个服务拖死。这个损失——用户流失、SLA违约、运维救火的人力成本——远比一个NVLink桥接器贵得多。
网上有位网友说过自己的纠结:"一直在犹豫买不买底板,如果NVLink没啥效果真没必要花大钱。"这个犹豫可以理解。但答案不是听别人说"有用"或"没用",而是用前面提到的nvidia-smi dmon方法,在自己的实际场景中测一测数据传输是否已经触顶。数据会告诉你答案。
结语:不要问NVLink有没有用,要问你的瓶颈在哪里
回到最开始的问题。NVLink到底有没有用?
这不是一个"有用/没用"的二元判断。它的价值完全取决于你的具体场景中,GPU间数据传输是否已经成为性能瓶颈。
如果你是个人用户,在本地跑跑模型、聊聊天,PCIe完全够用,省下的钱买杯咖啡犒劳自己。如果你是做生产级AI服务的,需要承载并发、保障SLA、避免尾部延迟引发的雪崩效应,那NVLink就是你不能省的一条工程底线。
做决策之前,别急着掏钱,也别急着听人推荐。先把推理任务跑起来,打开nvidia-smi dmon,看看你的GPU之间到底在搬运多少数据,PCIe的管子是不是已经被撑满了。
用数据指导选择,而不是用直觉。
最后,用一句话总结全文:
PCIe服务器适合跑模型,加了NVLink的才适合跑业务。