
科研及应用
GROMACS 与 GPU 加速:分子动力学模拟如何选显卡?
本文介绍分子动力学模拟的计算特点,解释 GROMACS 如何将高度并行的非键相互作用交给 GPU、将控制与约束等逻辑留在 CPU 端,形成典型的 CPU–GPU 协同架构。结合实测结果,说明 GPU 性能发挥高度依赖 CPU 配置和体系规模。最后给出本地和算力云的选卡与配比建议。
人工智能领域最新的科研成果,以及AI在科研领域的应用,包括深度学习、计算机视觉、高精度计算、仿真计算、分子动力学模拟等。
科研及应用
本文介绍分子动力学模拟的计算特点,解释 GROMACS 如何将高度并行的非键相互作用交给 GPU、将控制与约束等逻辑留在 CPU 端,形成典型的 CPU–GPU 协同架构。结合实测结果,说明 GPU 性能发挥高度依赖 CPU 配置和体系规模。最后给出本地和算力云的选卡与配比建议。
科研及应用
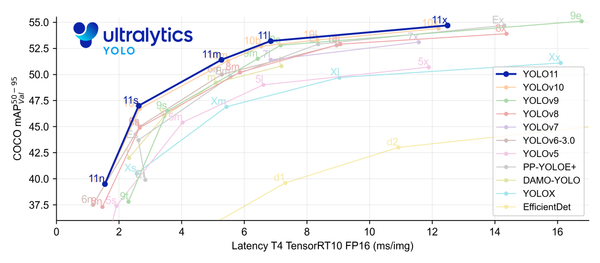
本文系统介绍了 YOLO 模型的核心思想与完整使用流程,从目标检测原理出发,结合真实工程实践,讲解了数据采集、标注、模型训练、参数理解以及部署验证等关键环节。文章强调 YOLO 的工程优势与可落地性,适合希望将目标检测真正用到实际场景中的开发者阅读。

科研及应用
本文探讨了AI框架与硬件的适配关系,以华为的CANN为例,详细介绍了其如何与MindSpore、PyTorch和TensorFlow等框架对接。文章分析了CANN与CUDA的对比,强调了昇腾NPU在AI计算中的优势以及CANN如何优化AI计算性能。通过对硬件与框架的深入了解,本文展示了AI硬件加速技术的关键要素。
科研及应用
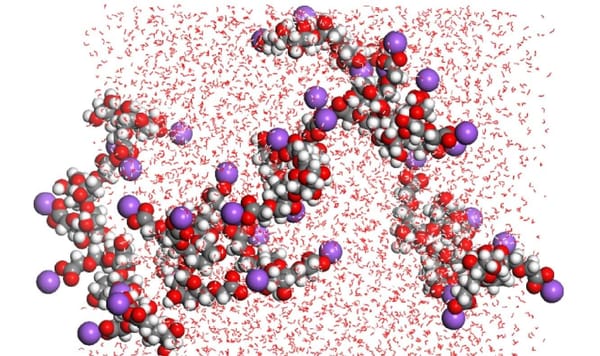
从分子动力学模拟的计算本质出发,系统梳理了个人用户选择硬件配置上的真实需求。 GPU 在分子模拟中的核心地位,为何英伟达显卡更具优势,主流软件GROMACS、LAMMPS对CUDA的支持;从实用角度分析了显卡、CPU等取舍逻辑。是选择租用云算力平台还是自购,适合学术论文、个人科研用户追求性价比的配置参考。