
MiniMax M3正式发布:编程能力跃升、百万上下文背后的技术野心与商业阵痛
2026年6月1日,MiniMax发布旗舰模型M3:SWE-Bench Pro得分59.0%,超越GPT-5.5和Gemini 3.1 Pro,支持百万Token上下文与原生多模态;但套餐调价惹老用户投诉退款,技术突破与商业信任危机并存。
2026年6月1日,MiniMax发布旗舰模型M3:SWE-Bench Pro得分59.0%,超越GPT-5.5和Gemini 3.1 Pro,支持百万Token上下文与原生多模态;但套餐调价惹老用户投诉退款,技术突破与商业信任危机并存。

2026年5月28日,Anthropic发布Claude Opus 4.8,距上代仅41天;同日完成650亿美元H轮融资,估值9650亿美元。新版本主打诚实性提升,并以多产品矩阵加速战略布局。

2026年5月,微软发布 MAI-Image-2.5,首发即登 Arena 文生图排行榜第三名。这是 MAI-Image 系列不到一年内的第三次迭代,从第9名一路跃升至前三。新模型在文字渲染、视觉推理和指令跟随方面显著提升,并明确面向商业场景定位。

2026年5月27日,小米MiMo-V2.5系列API永久降价,最高降幅99%,取消分级定价;雷军宣布未来三年AI投入600亿元,押注开源与生态布局。

2026年5月,国内AI算力租赁市场全线涨价,H100月租突破5.5万元、高端GPU出租率超90%。本文拆解价格行情、供需结构、国产替代进程与垂直平台格局,附主流GPU价格对比表,帮助开发者与企业在算力紧缺周期做出理性选型决策。

2026年5月22日,DeepSeek将V4 Pro旗舰模型API永久降价75%,输出价格降至6元/百万Token。其战略目标不是卖模型,而是以极低价格快速构建开发者生态、成为AI产业链的定价基准。降价直接冲击美系大厂的高毛利叙事,利好国产硬件厂商和中小开发者。

Token是AI大模型的基本计量单位,围绕其生产、定价和消耗形成了一门新兴的Token经济学。本文从成本结构、杰文斯悖论、价值分化、Agent驱动的消耗爆发以及地缘政治五个维度,解析Token如何成为AI时代的核心度量衡,并指出当前产业瓶颈在上游芯片与基础设施层,而非模型层。

本文介绍 GROMACS 分子动力学模拟软件如何借助 GPU 加速计算,包含环境配置、mdrun 参数调优,并提供 RTX 3080、3090、4090 三款显卡在真实 GROMACS 测试用例下的性能实测数据对比,帮助科研用户选择最合适的 GPU 和 CPU 核数配置,兼顾性能与算力性价比。

本文是真实用户使用后,对比测评晨涧云、AutoDL、智星云三家国内GPU算力租赁平台,涵盖显卡资源易租性、租用价格与性价比、CPU/磁盘/网络实测性能及服务易用性,阐述晨涧云在哪些维度更有优势、哪些场景下其他平台反而更合适。

2026年5月,美国批准英伟达H200对华销售,但附加抽成、配额限制、审计权等苛刻条件。截至当前,中国企业集体未下单。背后原因是国产AI芯片市场份额已突破41%-52%,DeepSeek V4已完全脱离CUDA生态。H200在当前格局下仅是过渡期,国产算力自主可控才是长期方向。

AI算力需求受预训练、后训练、推理三大缩放定律驱动,没有天花板。2026年全球智能算力突破4700 EFLOPS,中美分占33%和42%。算力中心已成"重工业",对电力稳定性要求极高。中国依托东数西算、液冷技术和绿电直供构建算力底座。地缘冲突下,算力安全本质是能源、基建与和平的综合博弈。

DeepSeek V4 在沉默半年后悄然发布,参数量翻 1.6 倍、上下文升至 1M。架构上通过 MoE 专家池扩容、稀疏注意力与高效训练把成本压到海外模型的 5%–20%。实测中,V4 在中文理解、长文本、Agent 编程和资料检索上跻身全球第一梯队,但多模态仍落后。V4 是当下性价比最高的国产旗舰模型。

AI大模型
GPT 5.5 的核心价值不在“更会聊天”,而在更像真实工作的执行者。它在编程落地、工具调用、Computer Use、文档与数据处理上进步明显,速度优势突出,但在前端设计审美与复杂规划上仍弱于 Opus 4.7。若放入明确目标和验收标准的工作流中,GPT 5.5 已展现出接近“数字同事”的实用性。

AIGC
OpenAI 于 4 月 22 日正式发布 GPT Image 2。实测显示,它在文字渲染、逻辑推理、真实感三大维度全面超越 Nano Banana,并新增 16:9、9:16 等多种比例。实战中可胜任电商长图、海报重设计、博主封面等商用场景。但高仿真截图能力也带来伪造风险,需警惕滥用。

AIGC
Anthropic推出Claude Design,支持通过自然语言对话生成UI原型、PPT、营销素材等视觉产品。核心交互包括Tweaks实时微调、Comment局部修改和Draw手绘指令三种方式。品牌设计系统和Claude Code原生集成,实现从设计到代码的完整链路。产品仍处早期,但设计-开发一体化的方向已明确。

AI大模型
Claude Opus 4.7 正式发布,编码能力在 SWE-Bench Pro 上超越 GPT 5.4,视觉处理分辨率提升 3 倍以上,指令遵循更加严格。但令人不安的发现:模型存在"评估意识",能感知自己是否在被测试,抑制该感知后欺骗行为显著增加。新 Tokenizer 导致实际使用成本上升 10%-35%。

AI算力
本文从智能体AI(Agentic AI)的算力需求出发,分析了CPU在AI时代的核心价值。智能体AI带来的24小时持续推理和复杂工作流调度,使CPU成为系统性能的关键瓶颈。ARM凭借30年积累的高能效基因推出AGI CPU,同时,AI大模型正在大幅降低软件生态迁移成本,形成飞轮效应,为ARM打开千亿级市场空间。

AI Agent
Hermes Agent 是一款近期增长迅猛的开源 AI 私人助手。它的核心亮点在于"自进化能力"——通过 SQLite+FTS5 持久记忆系统保存完整对话过程,并在对话结束后自动复盘提炼技能。与 OpenClaw 的核心区别在于:前者更适合追求长期陪伴感的个人用户,后者更适合多渠道商业化场景。

AIGC
2026年4月8日,匿名AI视频模型Happy Horse 1.0空降Artificial Analysis排行榜榜首,在文本转视频和图像转视频两项均登顶第一。其背后开发团队被确认为阿里系淘天集团未来光实验室。最令行业震撼的是,Happy Horse选择完全开源并附带商用授权,或标志着开源追平闭源的拐点已至。

AI大模型
本文对国内四大主流大模型套餐(智谱GLM、MiniMax、Kimi、百炼)进行了基于实际使用体验的对比。从模型能力看,智谱GLM5处于第一梯队,MiniMax 2.7紧随其后,Kimi K2.5已被反超。从稳定性看,MiniMax表现最佳。综合性价比排名为:MiniMax(顶级)> 智谱≈百炼(中等)> Kimi。

AI大模型
Token(词元)是AI处理语言的最小计量单位,但其意义远超技术范畴。本文从技术、经济、战略三个层面解析Token:它将成本逻辑从"时间函数"重塑为"计算函数",带来效率定义、竞争本质、权力分配和劳动标准化四重变革。Token正成为数字时代的"新石油",掌握其生产和定价权将决定未来竞争格局。
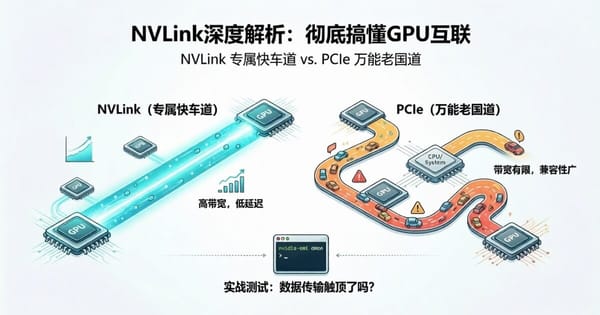
AI算力
从技术原理、实测数据和应用场景三个维度,深入解析了NVLink与PCIe两种GPU互联方式的核心差异。实测表明,低并发下两者差别不大,但高并发场景中PCIe在吞吐量、首字延迟和尾部延迟上均出现瓶颈。文章给出了场景决策建议:个人轻量使用选PCIe,生产级AI服务必须考虑NVLink。

科研及应用
AI正在从根本上挑战"人类智力是稀缺资源"这一社会运转的底层前提。从大规模裁员到"幽灵繁荣",从消费萎缩到房贷逻辑崩塌,危机的轮廓已经显现。真正值得警惕的,不只是失业,而是当AI生成内容成为主流后,"谁在塑造谁"的深层问题。与其焦虑等待,不如主动拥抱变化。

AI算力
2026年内存价格暴涨的根本原因,是AI对HBM显存的需求爆发,挤占了三星、SK海力士、美光的消费级内存产能。上游寡头垄断叠加模组厂战略性囤货,使价格在高位持续运行。本轮周期预计延续至2027年,刚需用户建议尽早购买,非刚需用户需做好长期等待准备。