
Kimi K3全解析:2.8万亿参数旗舰上线,智能体编程新答卷
月之暗面正式发布Kimi K3,官方确认2.8万亿参数、100万token上下文、原生多模态理解,主打软件工程与深度推理。本文梳理其架构细节、实测案例、评测数据、全渠道定价与开放计划,并给出K3与K2.7 Code、K2.6如何搭配使用的选型建议。
月之暗面正式发布Kimi K3,官方确认2.8万亿参数、100万token上下文、原生多模态理解,主打软件工程与深度推理。本文梳理其架构细节、实测案例、评测数据、全渠道定价与开放计划,并给出K3与K2.7 Code、K2.6如何搭配使用的选型建议。

OpenAI上周五一次性推出Sol、Terra、Luna三款GPT-5.6模型,同时把Codex并入ChatGPT桌面版,衍生出Work新模式。本文梳理三款模型的定位与价格、跑分与安全表现、产品架构变化,以及官方演示与民间实测之间的落差,帮不同用户判断该怎么用。

2026年7月8日,字节跳动正式发布Seedream 5.0 Pro,主打复杂信息可视化、局部精准编辑、真实影像质感和多语种生成四大能力。商业海报和产品摄影已达商用水准,但中文信息图错字、电商UI完成度和社交截图真实感仍是短板。与ChatGPT Images 2.0相比追赶势头明显,差距依然存在。

2026年7月晨涧云GPU算力资源全景盘点:从RTX 3060到A800 80G NVLink十种显卡的卡池规模、租卡难度、机器配置与价格优势一次看清。附按任务场景选卡指南、常见问题解答,帮你在"一卡难求"的行情下少走弯路,租对卡、花对钱。

2026年7月3日,阿里巴巴突然宣布全面禁用Claude系列产品。几个月前,公司还在为员工报销每周数百美元的Claude使用费。这场180度转变的背后,是Anthropic的蒸馏攻击指控、Claude Code被曝植入隐蔽标记系统,以及中美AI技术博弈下企业数据安全与供应链风险的全面爆发。

对比晨涧云与AutoDL两大GPU算力租赁平台在2026年7月的最新报价,覆盖RTX 3090、RTX 4090、A100 40G、A800 80G四款主流显卡的卡时、天租、周租、月租价格。晨涧云在3090和A100档位价格优势明显,长租折扣力度更大。

2026年6月30日,美团发布LongCat-2.0,总参数1.6万亿、激活参数约480亿,号称首个在五万卡国产算力集群完成全流程训练与推理的AI Agent模型,聚焦代码生成与长上下文。

2026年6月27日,OpenAI 突袭发布 GPT-5.6:Sol、Terra、Luna 登场。旗舰 Sol 跑分创新高却陷作弊争议,更关键的是美国介入下仅限预览,访问资格比性能更稀缺。

2026年6月27日,DeepSeek联合北大发布并开源DSpark推理加速框架,已用于DeepSeek-V4生产引擎,单用户生成速度提升60%-85%,高并发吞吐最高提升661%。
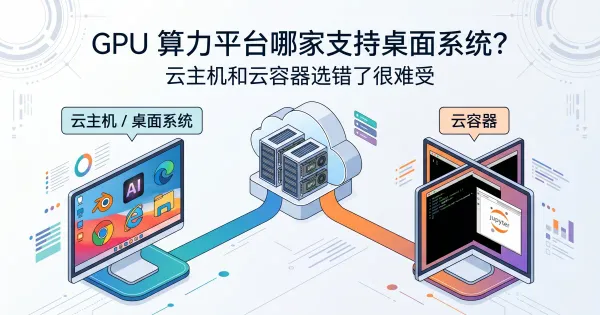
梳理三家支持桌面系统的 GPU 算力平台,对比云主机与云容器的实际差异。晨涧云所有显卡均支持云主机,Ubuntu 和 Windows 镜像选择最丰富;FunHPC 仅部分显卡支持云主机;OneThingAI 目前以 Windows 镜像为主。适合有图形界面需求、做 AIGC 或不熟悉命令行的用户参考。

AI应用进入生产环境后,API中转站的选择从"能调用"升级为"能稳定调用"。本文从模型覆盖、接口兼容、稳定性保障、成本结构、企业管理能力和合规本地化六个维度,结合不同场景的优先级差异,提供从测试到上线的完整接入实践,帮助企业和个人做出理性选择。

从Meta 8万员工竞相烧Token,到Uber全年AI预算不到年中已花光,再到某公司单月5亿美元账单却说不清买到了什么——AI支出在短短一年内从没人在意变成了头号难题。这篇文章梳理真实案例,拆解成本失控的底层逻辑,以及巨头们开始踩刹车背后的行业转折。

AI大模型
2026年6月12日Anthropic封停Fable 5全球访问,48小时后智谱全量开放GLM-5.2:1M上下文、自研ZCode 3.0、MIT开源商用,回应地缘变局下开发者对自主可控AI的需求。

AI大模型
2026年6月9日,Anthropic发布Claude Fable 5,首个公开Mythos级模型。SWE-Bench Pro 80.3%,代码迁移可从2个月缩至1天;但定价远高于DeepSeek,安全机制也引发争议。

AI大模型
2026年6月4日,OpenAI推出基于Dreaming V3的全新ChatGPT记忆架构:自动整合跨对话信息,无需手动“记住我”;算力降至1/5,美国Plus/Pro记忆容量翻倍,免费版将上线。

AI大模型
2026年6月1日,MiniMax发布旗舰模型M3:SWE-Bench Pro得分59.0%,超越GPT-5.5和Gemini 3.1 Pro,支持百万Token上下文与原生多模态;但套餐调价惹老用户投诉退款,技术突破与商业信任危机并存。

AI大模型
2026年5月28日,Anthropic发布Claude Opus 4.8,距上代仅41天;同日完成650亿美元H轮融资,估值9650亿美元。新版本主打诚实性提升,并以多产品矩阵加速战略布局。

AIGC
2026年5月,微软发布 MAI-Image-2.5,首发即登 Arena 文生图排行榜第三名。这是 MAI-Image 系列不到一年内的第三次迭代,从第9名一路跃升至前三。新模型在文字渲染、视觉推理和指令跟随方面显著提升,并明确面向商业场景定位。

AI大模型
2026年5月27日,小米MiMo-V2.5系列API永久降价,最高降幅99%,取消分级定价;雷军宣布未来三年AI投入600亿元,押注开源与生态布局。

AI算力
2026年5月,国内AI算力租赁市场全线涨价,H100月租突破5.5万元、高端GPU出租率超90%。本文拆解价格行情、供需结构、国产替代进程与垂直平台格局,附主流GPU价格对比表,帮助开发者与企业在算力紧缺周期做出理性选型决策。

AI大模型
2026年5月22日,DeepSeek将V4 Pro旗舰模型API永久降价75%,输出价格降至6元/百万Token。其战略目标不是卖模型,而是以极低价格快速构建开发者生态、成为AI产业链的定价基准。降价直接冲击美系大厂的高毛利叙事,利好国产硬件厂商和中小开发者。

AI大模型
Token是AI大模型的基本计量单位,围绕其生产、定价和消耗形成了一门新兴的Token经济学。本文从成本结构、杰文斯悖论、价值分化、Agent驱动的消耗爆发以及地缘政治五个维度,解析Token如何成为AI时代的核心度量衡,并指出当前产业瓶颈在上游芯片与基础设施层,而非模型层。

科研及应用
本文介绍 GROMACS 分子动力学模拟软件如何借助 GPU 加速计算,包含环境配置、mdrun 参数调优,并提供 RTX 3080、3090、4090 三款显卡在真实 GROMACS 测试用例下的性能实测数据对比,帮助科研用户选择最合适的 GPU 和 CPU 核数配置,兼顾性能与算力性价比。

AI算力
本文是真实用户使用后,对比测评晨涧云、AutoDL、智星云三家国内GPU算力租赁平台,涵盖显卡资源易租性、租用价格与性价比、CPU/磁盘/网络实测性能及服务易用性,阐述晨涧云在哪些维度更有优势、哪些场景下其他平台反而更合适。