AI算力
NVLink深度解析:从技术原理到实战性能,彻底搞懂GPU互联
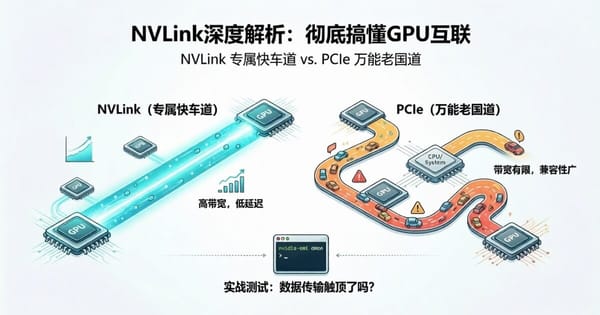
从技术原理、实测数据和应用场景三个维度,深入解析了NVLink与PCIe两种GPU互联方式的核心差异。实测表明,低并发下两者差别不大,但高并发场景中PCIe在吞吐量、首字延迟和尾部延迟上均出现瓶颈。文章给出了场景决策建议:个人轻量使用选PCIe,生产级AI服务必须考虑NVLink。
AI算力
从技术原理、实测数据和应用场景三个维度,深入解析了NVLink与PCIe两种GPU互联方式的核心差异。实测表明,低并发下两者差别不大,但高并发场景中PCIe在吞吐量、首字延迟和尾部延迟上均出现瓶颈。文章给出了场景决策建议:个人轻量使用选PCIe,生产级AI服务必须考虑NVLink。

科研及应用
AI正在从根本上挑战"人类智力是稀缺资源"这一社会运转的底层前提。从大规模裁员到"幽灵繁荣",从消费萎缩到房贷逻辑崩塌,危机的轮廓已经显现。真正值得警惕的,不只是失业,而是当AI生成内容成为主流后,"谁在塑造谁"的深层问题。与其焦虑等待,不如主动拥抱变化。

AI算力
2026年内存价格暴涨的根本原因,是AI对HBM显存的需求爆发,挤占了三星、SK海力士、美光的消费级内存产能。上游寡头垄断叠加模组厂战略性囤货,使价格在高位持续运行。本轮周期预计延续至2027年,刚需用户建议尽早购买,非刚需用户需做好长期等待准备。
AI Agent
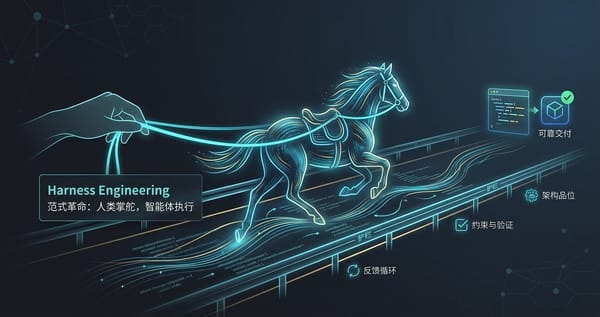
Harness Engineering是继Prompt Engineering和Context Engineering之后的第三次AI工程范式跃迁,核心理念是"人类掌舵,智能体执行"。本文系统拆解了Harness Engineering的技术架构与落地实践,并提供了五个可立即上手的核心原则。

AI算力
对比4080 Super 32GB魔改显卡、3090与4090在AI推理与训练中的表现,分析显存、带宽与Tensor算力差异,给出万元级GPU选型建议,适合大模型本地部署与算力规划参考。因为是魔改版本的显卡,建议在晨涧云算力平台先租用试试。
AI算力
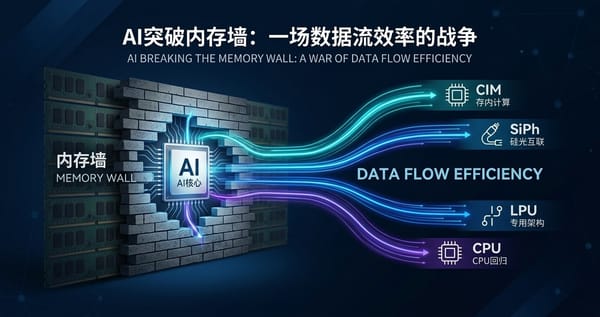
AI竞争正从算力堆砌转向数据流效率之争。传统GPU高达90%的能量消耗在数据搬运而非计算上,冯诺依曼架构的"内存墙"成为AI发展的真正瓶颈。业界分化出四条突围路径:存内计算消灭搬运,硅光互联用光子击穿带宽瓶颈,确定性/专用化架构牺牲灵活性换取极致效率,CPU回归实现数据流精细化治理。

AI算力
M5 Max通过引入Neural Accelerator实现矩阵运算性能最高3.5倍提升,将大模型推理首字响应时间(TTFT)缩短至M4 Max的三分之一,在多个模型测试中已正面超越上代M3 Ultra。M5 Max正从传统笔记本SoC向专业级AI计算卡演进,标志着苹果本地AI推理从"能用"迈向"好用"。

AI算力
本文从2GB到48GB逐级分析了不同显存容量的实际表现与适用场景。2GB、4GB已被淘汰;6GB明显落伍,8GB能用但上限将至;12GB是2026年主流玩家的甜点起步线,16GB兼顾游戏与创作;24GB面向专业生产力用户,48GB+则属于企业级工具。选显存的核心法则:匹配自身需求,拒绝盲目追大。

AI Agent
OpenClaw 的记忆系统通过四层分层架构、BM25 与向量语义混合搜索(7:3 加权)、指数时间衰减模型和四级嵌入降级链,解决了 AI Agent 每次重启失忆的根本问题。本文从源码架构到实战配置,全面解析这套让 Agent 真正"记住你"的设计哲学,并直面其安全隐患。

AI算力
本文对比 RTX 2080 Ti 22GB 与 RTX 3080 20GB 魔改版的核心规格、AI 推理与训练性能、价格性价比及适用场景。两张卡均针对本地大模型、LLM 推理、AIGC 生图等高显存需求,适合预算有限的开发者。3080 架构更新、带宽更高、整体性能更强;2080 Ti 显存略多、价格更低,各有侧重。

AI Agent
OpenClaw 是 GitHub 上增长最快的开源 AI Agent 项目,本文从架构原理、超级个体工作流、实际能做什么、能不能赚钱、国内落地难题五个维度全面拆解,附安装指引与模型选择建议,帮你判断它究竟值不值得折腾。

AI大模型
OpenAI于2026年3月6日发布GPT-5.4,首次将推理、编码和智能体能力整合至单一模型。核心升级包括:上下文窗口扩展至100万tokens、原生计算机操作能力、可中断思考过程、Fast模式及能力整合。在专业领域表现突出,标志着通用AI模型进入新阶段,为"全能型"模型树立了新标杆。