AI算力
AI为何被困在内存墙中:一场从算力堆砌到数据流效率的战争
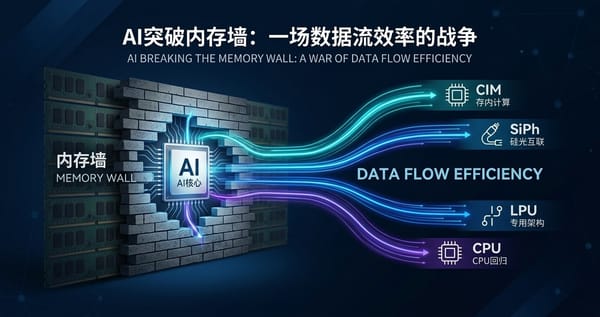
AI竞争正从算力堆砌转向数据流效率之争。传统GPU高达90%的能量消耗在数据搬运而非计算上,冯诺依曼架构的"内存墙"成为AI发展的真正瓶颈。业界分化出四条突围路径:存内计算消灭搬运,硅光互联用光子击穿带宽瓶颈,确定性/专用化架构牺牲灵活性换取极致效率,CPU回归实现数据流精细化治理。
GPU显卡资源,英伟达(NVIDIA)最新的H100、H200、B200以及普遍使用的RTX 4090、RTX 3090、A100等;算力基础设施、算力租赁与云服务,AI专用实例、算力集群服务、定价策略等;算力性能基准测试,性能排行榜,及一些在特定场景下最适合的GPU选型等。
AI算力
AI竞争正从算力堆砌转向数据流效率之争。传统GPU高达90%的能量消耗在数据搬运而非计算上,冯诺依曼架构的"内存墙"成为AI发展的真正瓶颈。业界分化出四条突围路径:存内计算消灭搬运,硅光互联用光子击穿带宽瓶颈,确定性/专用化架构牺牲灵活性换取极致效率,CPU回归实现数据流精细化治理。

AI算力
M5 Max通过引入Neural Accelerator实现矩阵运算性能最高3.5倍提升,将大模型推理首字响应时间(TTFT)缩短至M4 Max的三分之一,在多个模型测试中已正面超越上代M3 Ultra。M5 Max正从传统笔记本SoC向专业级AI计算卡演进,标志着苹果本地AI推理从"能用"迈向"好用"。

AI算力
本文从2GB到48GB逐级分析了不同显存容量的实际表现与适用场景。2GB、4GB已被淘汰;6GB明显落伍,8GB能用但上限将至;12GB是2026年主流玩家的甜点起步线,16GB兼顾游戏与创作;24GB面向专业生产力用户,48GB+则属于企业级工具。选显存的核心法则:匹配自身需求,拒绝盲目追大。

AI算力
本文对比 RTX 2080 Ti 22GB 与 RTX 3080 20GB 魔改版的核心规格、AI 推理与训练性能、价格性价比及适用场景。两张卡均针对本地大模型、LLM 推理、AIGC 生图等高显存需求,适合预算有限的开发者。3080 架构更新、带宽更高、整体性能更强;2080 Ti 显存略多、价格更低,各有侧重。

AI算力
谷歌、亚马逊、SpaceX、英伟达正竞相将AI数据中心送入太空。太空提供近乎免费的太阳能、极端散热条件与超低延迟通信,但发射成本、散热工程、辐射防护与轨道拥挤等挑战仍横亘在前。本文全面拆解太空算力的三大优势、真实成本、产业路径与现实瓶颈。

AI算力
2026年2月14日,美光官宣全球首款面向数据中心的 PCIe Gen6 固态硬盘 9650 系列正式量产,顺序读取高达 28GB/s,较 PCIe 5.0 读速翻倍、能效提升最高 2 倍,搭载第九代 G9 TLC NAND 颗粒。本文全面解析其核心参数、两款子系列定位、散热设计及对 AI 算力基建的深远意义。

AI算力
本文梳理了算力从芯片、本地计算到云计算的发展过程,解释了 AI 时代算力需求为何远超摩尔定律,引发全球“算力战争”。对比了中美在算力布局上的不同路径,并解析欧洲、日本的差异化策略,重点讨论太空算力在能源、散热和效率上的潜在优势。强调算力既是国家战略资源。

AI算力
A100显卡价格暴跌超50%,40GB版2.8-4元/小时,80GB版4-6.5元/小时,包月9800-30000元。相比H100便宜70%,显存40-80GB适合大模型微调和推理。国产昇腾910B月租2万元形成竞争。供给充足、推理需求上升、价格战常态化。短期项目按需计费,长期包月省20-50%。

AI算力
AI算力租赁是云端共享显卡服务,按需计费无需购买硬件。2026年中国市场规模达2600亿元,年增速20%以上。分为云巨头(阿里云、腾讯云)、专业平台(AutoDL、晨涧云)和差异化平台三类。推理需求占比上涨,国产芯片加速替代。从"买卡"到"租服务",从裸算力到MaaS,AI算力成为新型基础设施。

AI算力
根据VideoCardz对10个国家和地区的14款当代显卡最低现货价格统计,过去三个月间全球显卡价格平均上涨15%。RTX 5090全球均涨32%,RTX 5070 Ti紧随其后,均涨25%。中国国内,涨幅最高的反而是RTX 5060 Ti 16G,达23.08%。AMD和Intel整体表现较为克制。

AI算力
2025年GPU算力租赁市场突破千亿规模,但价格大幅回落超70%。市场从"抢卡"转向"拼交付",推理需求快速崛起预计2028年占比达73%。企业竞争焦点转向异构调度、绿色能效和生态服务能力。东数西算与算力券政策强力引导,液冷技术使PUE降至1.1,行业迈向高质量发展阶段。

AI算力
本文围绕近期出现的 32GB 魔改版 RTX 5080 显卡展开,梳理了其来源、改装方式及面向的本地 AI 运算市场。解释了为何在大模型推理场景下,显存容量往往比纯算力更关键,以及 32GB 版 5080 如何以低于 5090 的成本填补高显存需求空档。