晨涧云文档
首页
目录
- GPU算力租用流程
- Ubuntu查看显卡GPU利用率
- Ubuntu系统安装CUDA Toolkit + Cudnn
- Ubuntu NVIDIA显卡驱动安装
- Ubuntu用户界面入门
- Windows jupter notebook 的使用
- Windows 安装SSH Server
- windows查看显卡GPU利用率
- Ubuntu镜像
- Windows镜像
- CentOS镜像
- 深度学习 - Ubuntu
- 深度学习 - Windows
- ComfyUI - Ubuntu
- LLaMA Factory - Ubuntu
- Stable Diffusion - Ubuntu
- Ubuntu 命令行使用
- ComfyUI - Windows
- LLaMA Factory - Windows
- Stable Diffusion - Windows
- 秋叶Stable Diffusion - Windows
- Ollama - Windows
- Ollama DeepSeek - Ubuntu
- 【模型】Ollama + Open WebUI - Ubuntu
- 【语音】 Whisper 语音转文本 - Ubuntu
- Chatbox - Windows
- Ubuntu系统安装远程连接工具
- Windows登录方式
- 晨涧云概览
- 晨涧云简介
- 名词术语
- Windows安装显卡驱动
- 连接失败处理
- 促销活动
- Miniconda3 容器镜像
- PyTorch 容器镜像
- TensorFlow 容器镜像
- GROMACS 容器镜像
- ComfyUI 容器镜像
- Matlab - Windows
- YOLO 容器镜像
- LLaMA-Factory 容器镜像
- Wan-ComfyUI 容器镜像
- Stable-Diffusion 容器镜像
- vLLM 容器镜像
- LAMMPS 容器镜像
- Ollama 容器镜像
- Flux-ComfyUI 容器镜像
- ComfyUI应用
- Wan2.2文生视频显卡性能测试
- 深度学习场景
- 基于ResNet-50模型的显卡性能测试
- 大语言模型场景
- 使用vLLM测试大模型推理场景的显卡性能
- Qwen-ComfyUI 容器镜像
- vLLM大模型多卡推理场景显卡测试
- 科研仿真计算场景
- GROMACS分子动力学模拟计算显卡性能测试
- 【年终满减优惠活动】全系显卡算力特惠风暴!(A100除外)
- YOLO 模型训练显卡性能测试
- FluxGym-LoRA训练器 容器镜像
- Kohya_ss-LoRA训练器 容器镜像
- OpenClaw 容器镜像
- VSCode连接常见问题
- OpenClaw镜像 - Ubuntu
- OpenClaw镜像 - Windows
- OpenClaw应用
- OpenClaw本地Ollama模型调用实测
- OpenClaw创建飞书应用机器人实测
- OpenClaw晨涧云大模型API调用实测
- Ansys-Windows
- 学术资源加速
- 文件传输
- RustDesk远程连接
- 常见问题集
- RustDesk远程手机端设置
- PyCharm连接云主机
- WebUI使用
- 服务端口配置
- SSH隧道映射端口
- VSCode连接到云主机
- conda 安装虚拟环境
- 选择Conda虚拟环境
- 安装tensorflow
- huggingface下载模型
- 晨涧云服务协议
- 晨涧云反挖矿协议
- pip&conda安装换源
- Anaconda环境迁移
- 晨涧云平台手册
- Windows操作
- GPU算力操作流程
- 云容器租用流程
- 系统预装环境
- Ubuntu操作
- 云容器控制台使用
- 云主机控制台使用
- JupyterLab使用
- 云主机镜像中心
- 云容器百度网盘使用
- 云容器
- 云容器按小时计费
- 云容器镜像
- 常见问题(FAQ)
- 常用操作
- 技术相关
- 应用场景
- 服务协议
- 晨涧云新老用户专享福利
- 微信登录立享6元优惠券
- 晨涧云产品重磅升级:云容器按量计费+控制台实例管理全新改版,重塑AI开发效率与成本体验
- 新容器镜像来了!宝藏镜像库+秒级部署,GPU直接8折!
- 【双十一显卡狂欢】🔥NVIDIA 3090/3080 史低八折!性能猛兽,价格温柔!
- 开学季|3090显卡专属福利🎯(2025年9月)
使用vLLM测试大模型推理场景的显卡性能
晨涧云AI算力平台的云容器支持Ollama、vLLM等大模型推理镜像,Ollama简单易用,更适合桌面环境或者简单试用,vLLM则更适合对吞吐要求高的高并发生产环境。
所以这里选择使用vLLM云容器来比较下3090和4090这两张显卡在大模型推理场景下的算力表现。
选择大模型
选择 Qwen3的模型进行测试,考虑到都是24GB的显存,选择的是FP16精度的qwen3:8b模型进行测试。
借助ChatGPT 生成测试脚本,调整脚本控制变量:
使用复杂度近似的N个prompts;
MAX_TOKENS配置256,让每次请求需要一定的生成时长便于采样显卡的使用指标,减少波动;选择
[1, 4, 8, 16]4种BATCH_SIZES测试不同并发度下的性能表现;每轮测试执行3次推理,指标取平均;
同时需要模型预热,消除第一次推理响应延时过大的问题。
然后执行推理性能测试脚本,查看输出结果。
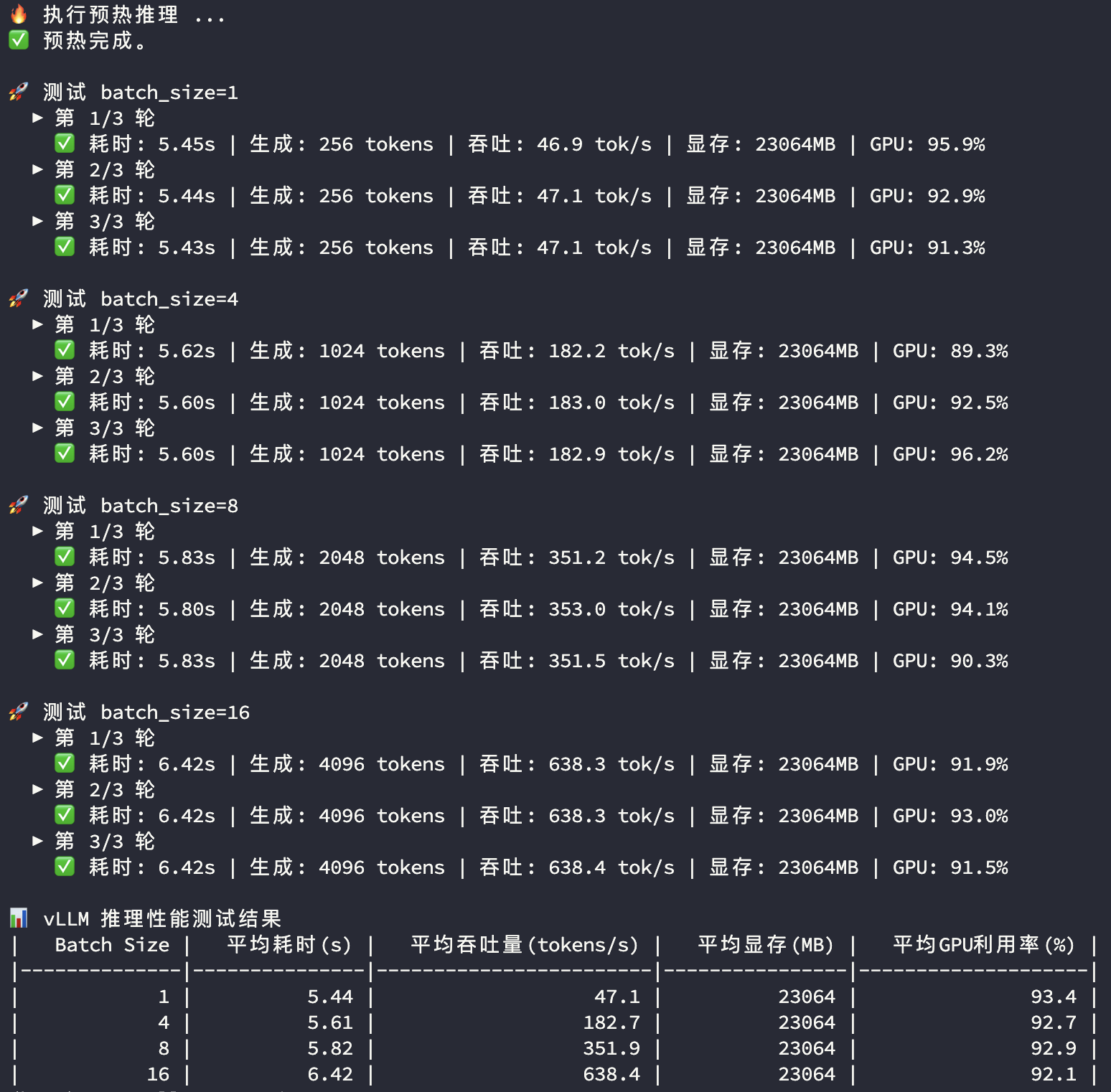
3090显卡大模型推理实测
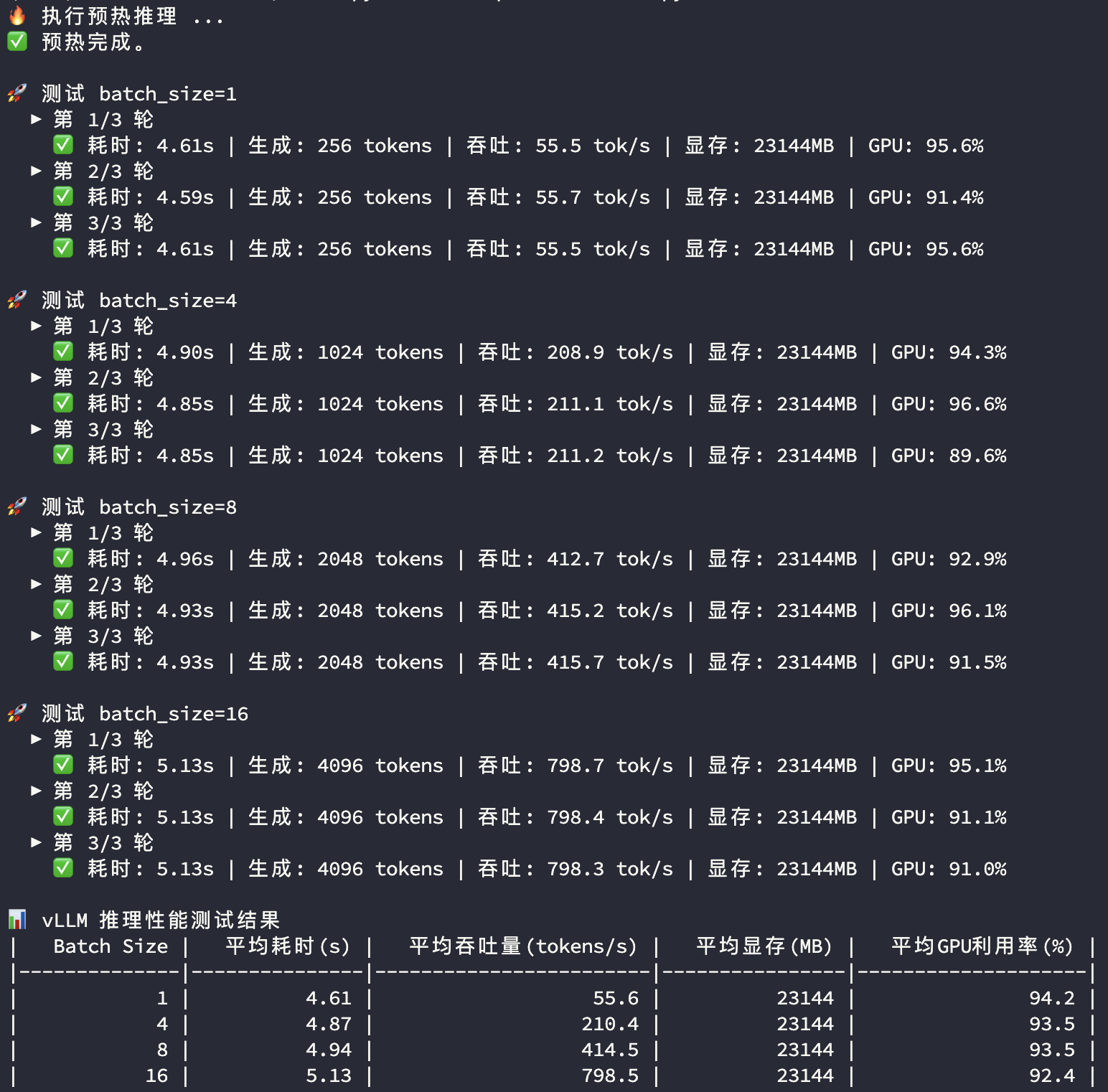
4090显卡大模型推理实测
测试结果分析
Batch Size:一次推理调用的并发prompt数量
平均耗时 (s):多次推理平均响应时长
平均吞吐量 (tokens/s):多次推理平均Token生成速度
平均显存 (MB):多次推理平均显存使用量
平均GPU使用率(%):多次推理平均GPU使用率
3090显卡和4090显卡在模型推理过程中的显存和GPU使用率都比较接近,主要看平均耗时及平均吞吐量两个指标:
| BatchSize | 指标 | RTX3090 | RTX4090 | 对比 |
|---|---|---|---|---|
| 1 | 平均耗时(s) | 5.44 | 4.61 | |
| 1 | 平均吞吐量(tokens/s) | 47.10 | 55.60 | 118.0% |
| 4 | 平均耗时(s) | 5.61 | 4.87 | |
| 4 | 平均吞吐量(tokens/s) | 182.70 | 210.40 | 115.2% |
| 8 | 平均耗时(s) | 5.82 | 4.94 | |
| 8 | 平均吞吐量(tokens/s) | 351.90 | 414.50 | 117.8% |
| 16 | 平均耗时(s) | 6.42 | 5.13 | |
| 16 | 平均吞吐量(tokens/s) | 638.40 | 798.50 | 125.1% |
BatchSize低于8的并发度场景下,4090的推理性能比3090高17%左右,且性能表现相对稳定;在16并发度下3090开始遇到性能瓶颈,而4090还有比较充足的性能空间。