vLLM大模型多卡推理场景显卡测试
晨涧云AI算力平台的云容器支持Ollama、vLLM等大模型推理镜像。当大模型的参数量过大,单张显卡的显存无法装下时,可以使用多卡部署大模型进行推理,vLLM更适合多卡高吞吐的模型推理场景。
单卡大模型推理显卡性能测试请参考:
使用vLLM测试大模型推理场景的显卡性能
下面使用vLLM测试多卡推理场景下3090和4090两张显卡的性能表现。
大模型选择
两张卡都是24G显存,选择 Qwen3-14B的模型进行测试。
测试脚本控制部署和推理的参数一致:
使用复杂度近似的N个prompts;
MAX_TOKENS配置256,让每次请求需要一定的生成时长便于采样显卡的使用指标,减少波动;选择
[1, 4, 8, 16]4种BATCH_SIZES测试不同并发度下的性能表现;每轮测试执行3次推理,指标取平均;
同时需要模型预热,消除第一次推理响应延时过大的问题;
显卡的显存占用和GPU使用率指标使用两卡相加的值。
执行测试脚本,查看输出结果:
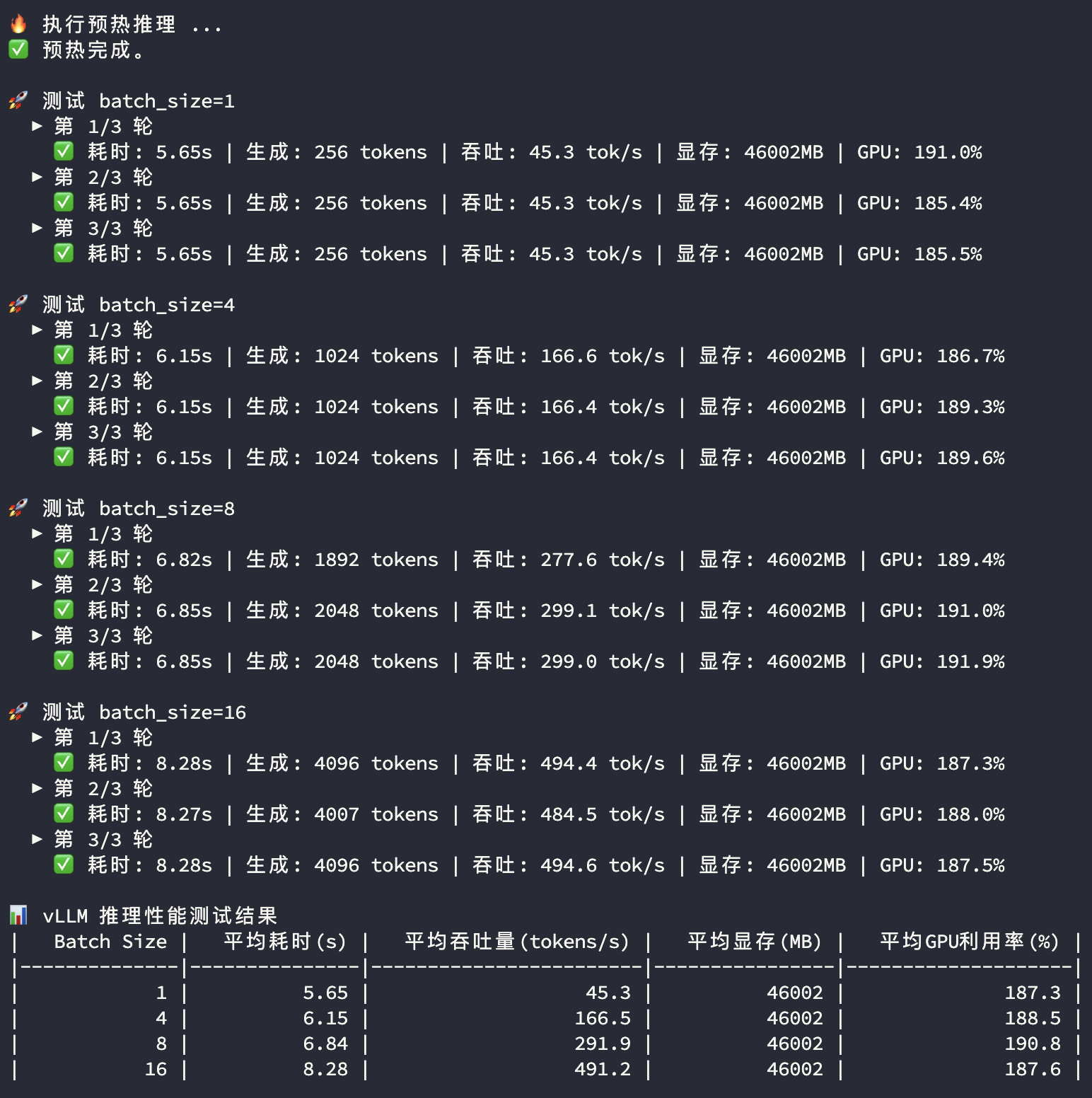
3090多卡推理
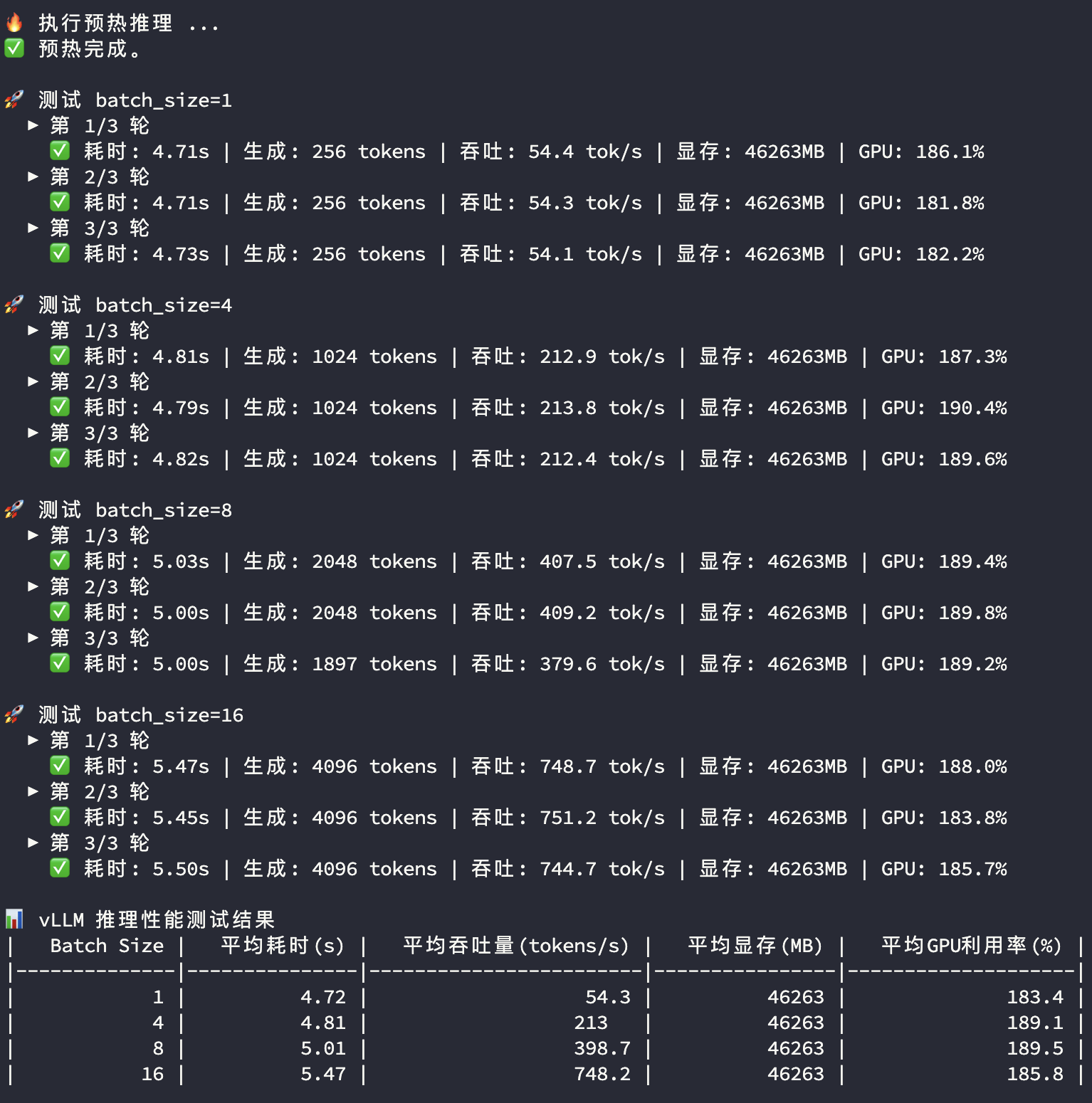
4090多卡推理
测试结果分析
Batch Size:一次推理调用的并发prompt数量
平均耗时 (s):多次推理平均响应时长
平均吞吐量 (tokens/s):多次推理平均Token生成速度
平均显存 (MB):多次推理平均显存使用量,两卡相加
平均GPU使用率(%):多次推理平均GPU使用率,两卡相加
3090显卡和4090显卡在多卡模型推理过程中的显存和GPU使用率都比较接近,主要关注平均耗时及平均吞吐量两个指标:
| BatchSize | 指标 | 双卡3090 | 双卡4090 | 对比 |
|---|---|---|---|---|
| 1 | 平均耗时(s) | 5.65 | 4.72 | |
| 1 | 平均吞吐量(tokens/s) | 45.3 | 54.3 | 119.9% |
| 4 | 平均耗时(s) | 6.15 | 4.81 | |
| 4 | 平均吞吐量(tokens/s) | 166.5 | 213.0 | 127.9% |
| 8 | 平均耗时(s) | 6.84 | 5.01 | |
| 8 | 平均吞吐量(tokens/s) | 291.9 | 398.7 | 136.6% |
| 16 | 平均耗时(s) | 8.28 | 5.47 | |
| 16 | 平均吞吐量(tokens/s) | 491.2 | 748.2 | 152.3% |
从平均耗时来看,低并发(1–8)时,4090 的延迟几乎持平,性能随并发线性爬升;拉到 16 并发,也只是轻微下滑。而 3090 在 1–8 并发区间里延迟逐级抬升,到 16 并发时陡增,衰减幅度明显大于 4090。
平均吞吐的数据也能印证这一点:并发从 1 加到 16,两款卡的差距被持续放大,16 并发下 4090 的吞吐量大约是 3090 的 1.5 倍。
如何选择?
延迟稳:4090 凭更强的核心和更大的 L2,在小并发场景就能把延迟压得很稳。
吞吐高:高并发时 4090 的 Tokens/s 比 3090 高 50% 以上,同时满足更多用户并发使用也更快。
性价比:自己尝试或使用量较小的场景,选 3090 ;追求对外服务的稳定性或高并发场景,选 4090。